'%20style='fill:%20%231a365d'/%3e%3c/g%3e%3cg%20id='patch_3'%3e%3cpath%20d='M%20360%20624.76833%20C%20430.217382%20624.76833%20497.568295%20596.870668%20547.219481%20547.219481%20C%20596.870668%20497.568295%20624.76833%20430.217382%20624.76833%20360%20C%20624.76833%20289.782618%20596.870668%20222.431705%20547.219481%20172.780519%20C%20497.568295%20123.129332%20430.217382%2095.23167%20360%2095.23167%20C%20289.782618%2095.23167%20222.431705%20123.129332%20172.780519%20172.780519%20C%20123.129332%20222.431705%2095.23167%20289.782618%2095.23167%20360%20C%2095.23167%20430.217382%20123.129332%20497.568295%20172.780519%20547.219481%20C%20222.431705%20596.870668%20289.782618%20624.76833%20360%20624.76833%20z%20'%20clip-path='url(%23pa684379385)'%20style='fill:%20%232b6cb0'/%3e%3c/g%3e%3cg%20id='patch_4'%3e%3cpath%20d='M%20360%20517.601082%20C%20401.796295%20517.601082%20441.88635%20500.995238%20471.440794%20471.440794%20C%20500.995238%20441.88635%20517.601082%20401.796295%20517.601082%20360%20C%20517.601082%20318.203705%20500.995238%20278.11365%20471.440794%20248.559206%20C%20441.88635%20219.004762%20401.796295%20202.398918%20360%20202.398918%20C%20318.203705%20202.398918%20278.11365%20219.004762%20248.559206%20248.559206%20C%20219.004762%20278.11365%20202.398918%20318.203705%20202.398918%20360%20C%20202.398918%20401.796295%20219.004762%20441.88635%20248.559206%20471.440794%20C%20278.11365%20500.995238%20318.203705%20517.601082%20360%20517.601082%20z%20'%20clip-path='url(%23pa684379385)'%20style='fill:%20%2363b3ed'/%3e%3c/g%3e%3cg%20id='patch_5'%3e%3cpath%20d='M%20360%20457.402825%20C%20385.831531%20457.402825%20410.608547%20447.139849%20428.874198%20428.874198%20C%20447.139849%20410.608547%20457.402825%20385.831531%20457.402825%20360%20C%20457.402825%20334.168469%20447.139849%20309.391453%20428.874198%20291.125802%20C%20410.608547%20272.860151%20385.831531%20262.597175%20360%20262.597175%20C%20334.168469%20262.597175%20309.391453%20272.860151%20291.125802%20291.125802%20C%20272.860151%20309.391453%20262.597175%20334.168469%20262.597175%20360%20C%20262.597175%20385.831531%20272.860151%20410.608547%20291.125802%20428.874198%20C%20309.391453%20447.139849%20334.168469%20457.402825%20360%20457.402825%20z%20'%20clip-path='url(%23pa684379385)'%20style='fill:%20%23ebf8ff'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='pa684379385'%3e%3crect%20x='0'%20y='0'%20width='720'%20height='720'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Privacy-Preserving Transfer Learning Framework for Building Energy Forecasting with Fully Anonymized Data
A novel framework that enables effective transfer learning using exclusively anonymized time-series data, achieving median MSE reductions of 27–31% across 89 real-world buildings while requiring only 0.51% of federated learning's communication bandwidth.
Abstract
AI-driven forecasting offers a promising solution for optimal building energy control, yet is constrained by scarce labeled data and strict privacy regulations. While transfer learning (TL) can alleviate data scarcity by leveraging data from other buildings, conventional TL relies on metadata unavailable in fully anonymized datasets. We propose a Privacy-Preserving Transfer Learning (PPTL) framework that overcomes this deadlock by learning similarity directly from anonymized time-series dynamics.
Using an unsupervised contrastive encoder, the framework maps each building’s dynamics to high-dimensional representation vectors learned solely from temporal patterns. Cosine distance between representations guides source selection to pretrain a lightweight forecaster, which is then fine-tuned on limited target data.
Leave-one-out experiments on 89 real-world buildings validate that learned similarity strongly correlates with transfer performance: models pretrained on highly similar sources achieve median MSE reductions of 27–31%, peaking at 31% with optimal configurations, compared to target-only baselines. The framework improves forecasting in 99.2% of configurations (353 of 356), with only three instances showing marginal degradation (maximum 2.2%).
Motivation: The Privacy–Performance Deadlock
Building energy efficiency is a critical mandate for global decarbonization—buildings account for about 37% of CO₂ emissions. AI has emerged as a powerful tool for energy forecasting, but the building sector faces two structural barriers:
- Heterogeneity — Each building is a unique system defined by distinct materials, form, usage patterns, and microclimates, resisting one-size-fits-all modeling.
- Privacy — Energy patterns reveal occupancy behaviors and business operations. Regulations like GDPR strictly restrict data sharing.
These barriers create a paradox: heterogeneity demands diverse training data from many buildings, yet privacy prevents the data aggregation needed to compile such datasets. Transfer learning could bridge this gap, but conventional methods rely on metadata (building type, size, climate zone) that anonymization removes—creating a methodological deadlock.
The PPTL Framework
Our framework shifts the paradigm from metadata-based heuristics to data-native learned similarity. Three modular components work in sequence:
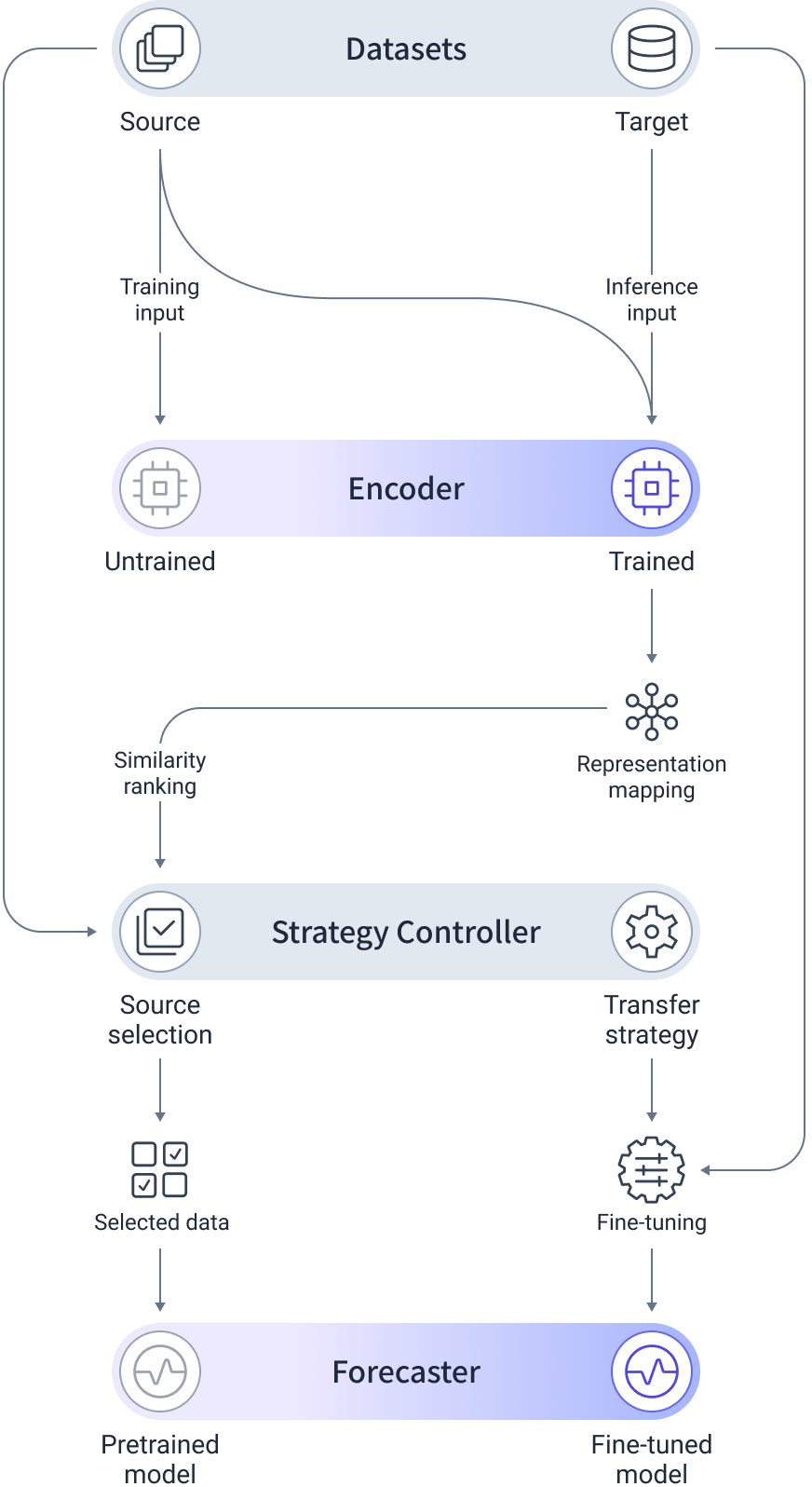
1. TS2Vec Encoder — Unsupervised Contrastive Learning
The encoder employs TS2Vec, a time-series contrastive learning model that learns representations from unlabeled, anonymized data. Unlike image-based contrastive learning, TS2Vec uses contextual consistency: the representation of a timestamp must remain consistent regardless of the temporal window from which it is viewed.
This approach captures temporal dependencies and operational logic—diurnal cycling, seasonal periodicity, load-shape dynamics—without requiring metadata or manual feature engineering.
2. TiDE Forecaster — Lightweight and Efficient
The forecasting module uses TiDE (Time-series Dense Encoder), an MLP-based encoder-decoder model that scales linearly and supports full parallel computation.
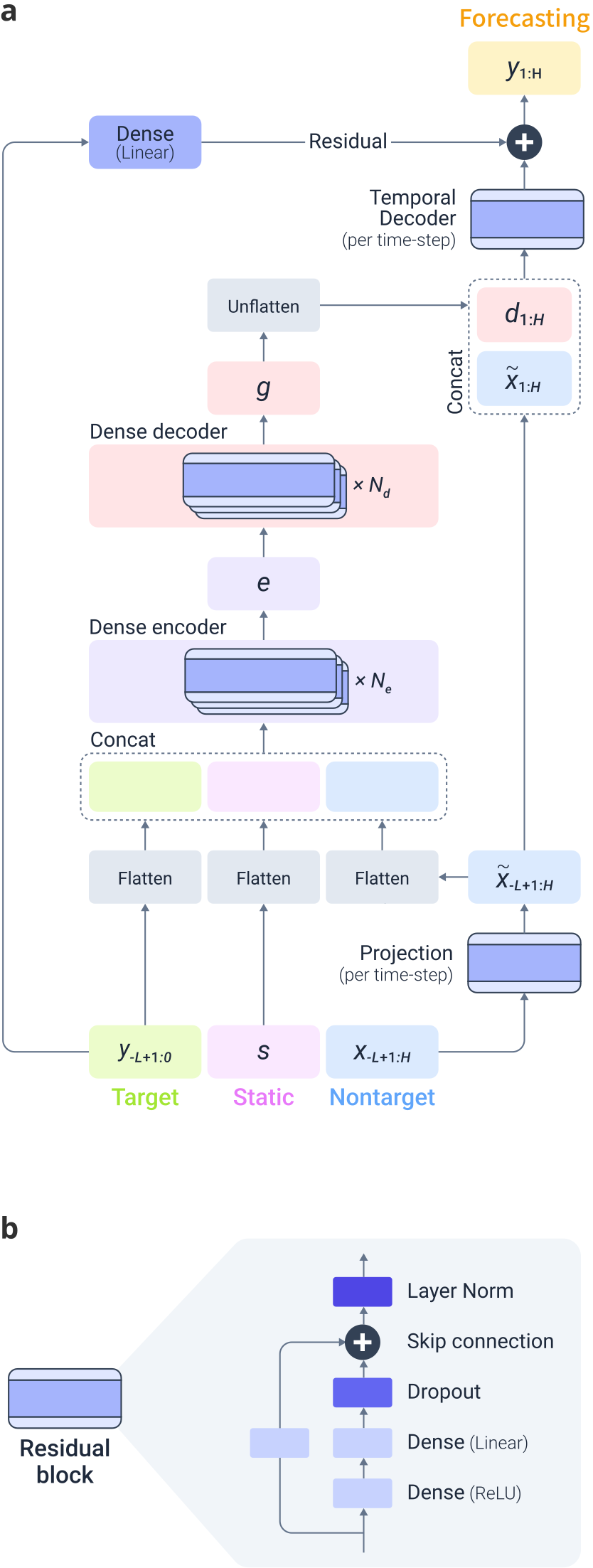
TiDE processes historical target features, static features (anonymized building index), and nontarget covariates (weather, time indicators) through a dense encoder-decoder architecture with residual connections and dropout.
3. Strategy Controller — Source Selection
The controller orchestrates similarity-based source selection using cosine distance in the learned representation space, then manages a two-stage learning process:
- Pretraining on top-ranked source buildings
- Full fine-tuning on limited target data
Workflow
The PPTL framework follows a systematic four-step pipeline:
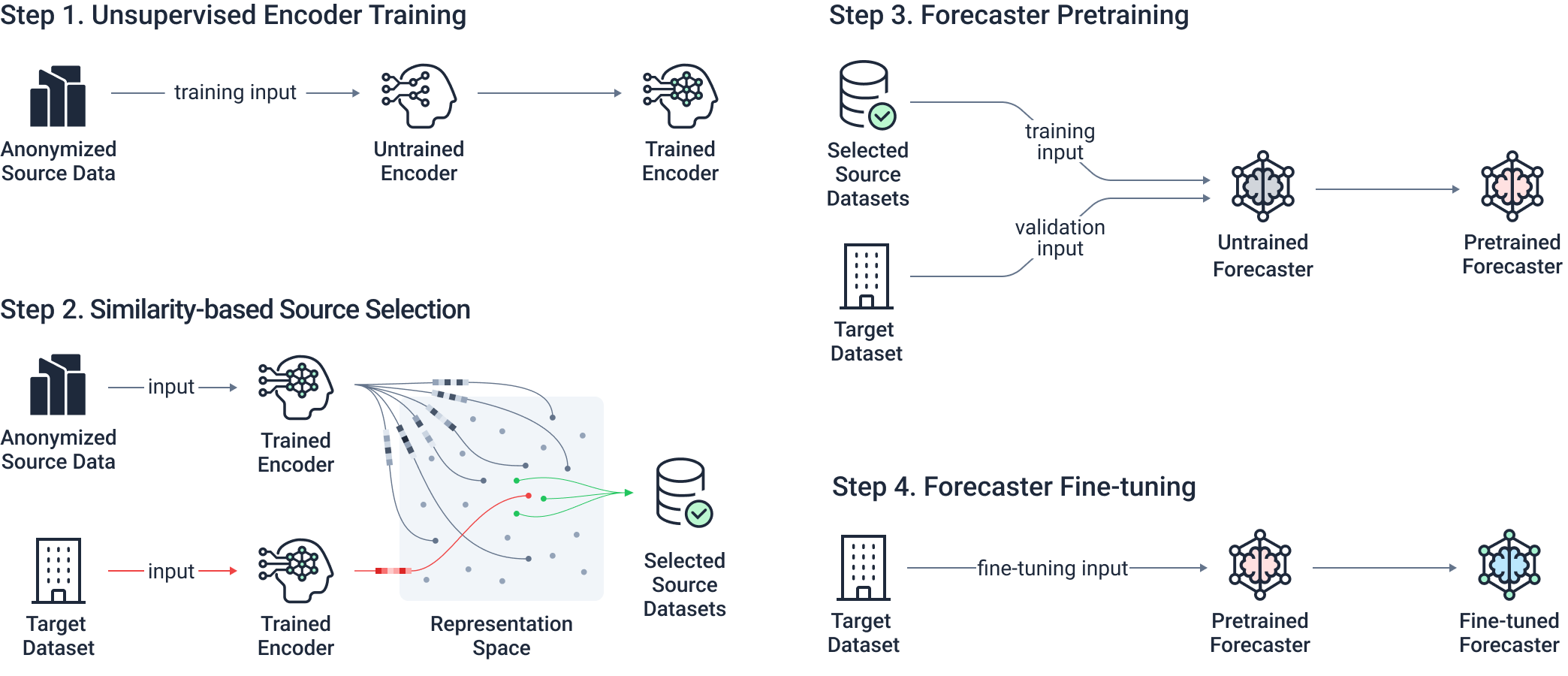
Step 1. Train the TS2Vec encoder on anonymized source data to construct the latent representation space.
Step 2. Generate representations for source and target buildings, then rank sources by cosine distance.
Step 3. Pretrain the TiDE forecaster on the most similar source datasets.
Step 4. Fine-tune the pretrained model on limited target data to produce the final forecaster.
Dataset
The framework is validated using the Cambridge University Estates building energy archive—24 years of hourly electricity usage from ~120 fully anonymized buildings including lecture halls, offices, laboratories, and museums. All building information is completely anonymized: each building is identified only by a randomized numerical index.
We curate a 16-month interval with 89 gap-free buildings. The first 14 months are used for model development and the final 2 months for testing.
Results
Learned Similarity Captures Operational Patterns
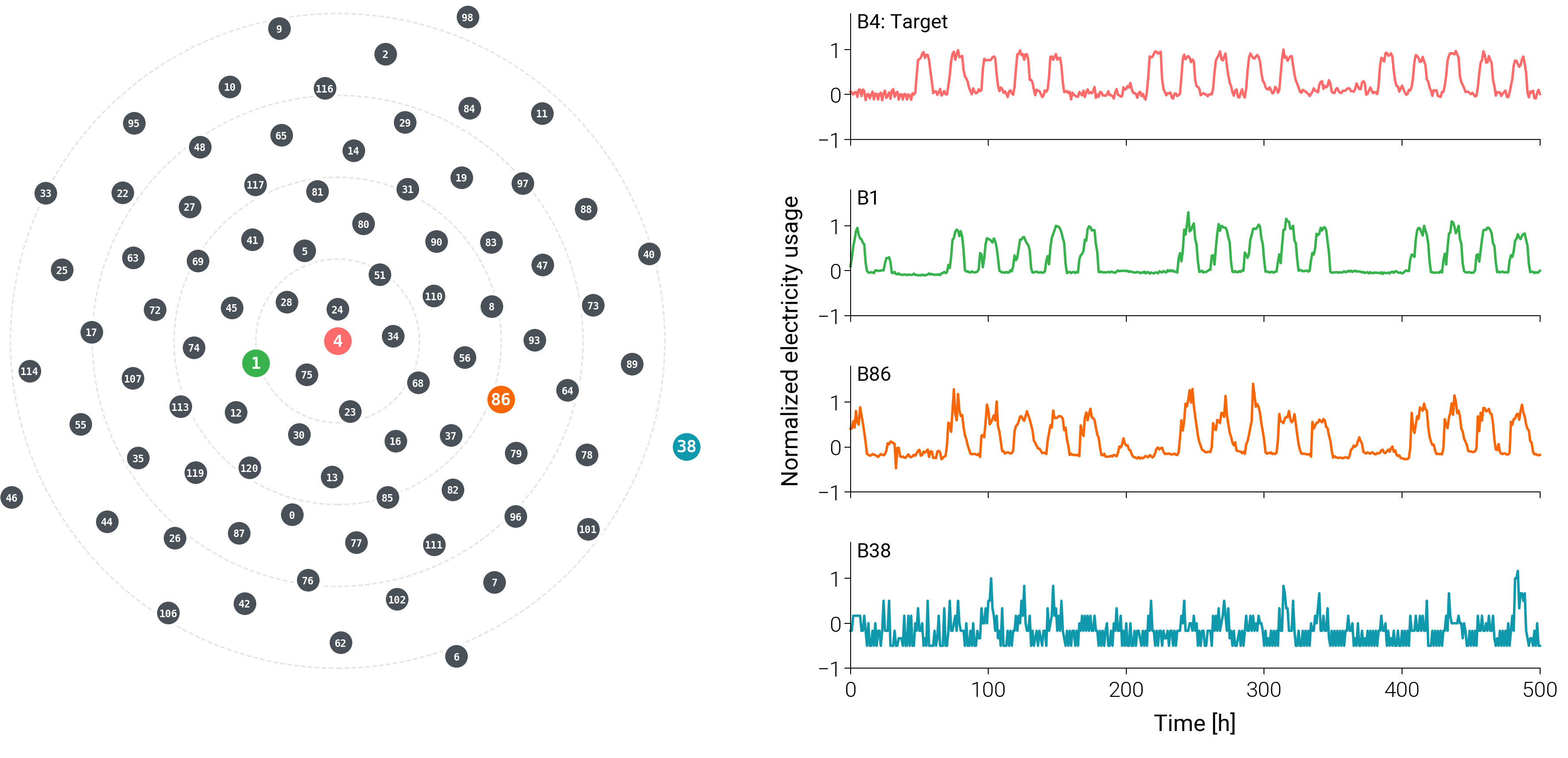
The 2D visualization confirms that proximity in the learned space correlates with actual operational similarity—nearest buildings show nearly identical weekly patterns, while farthest buildings display irregular profiles incompatible with the target.
Source Selection Strategy Validation
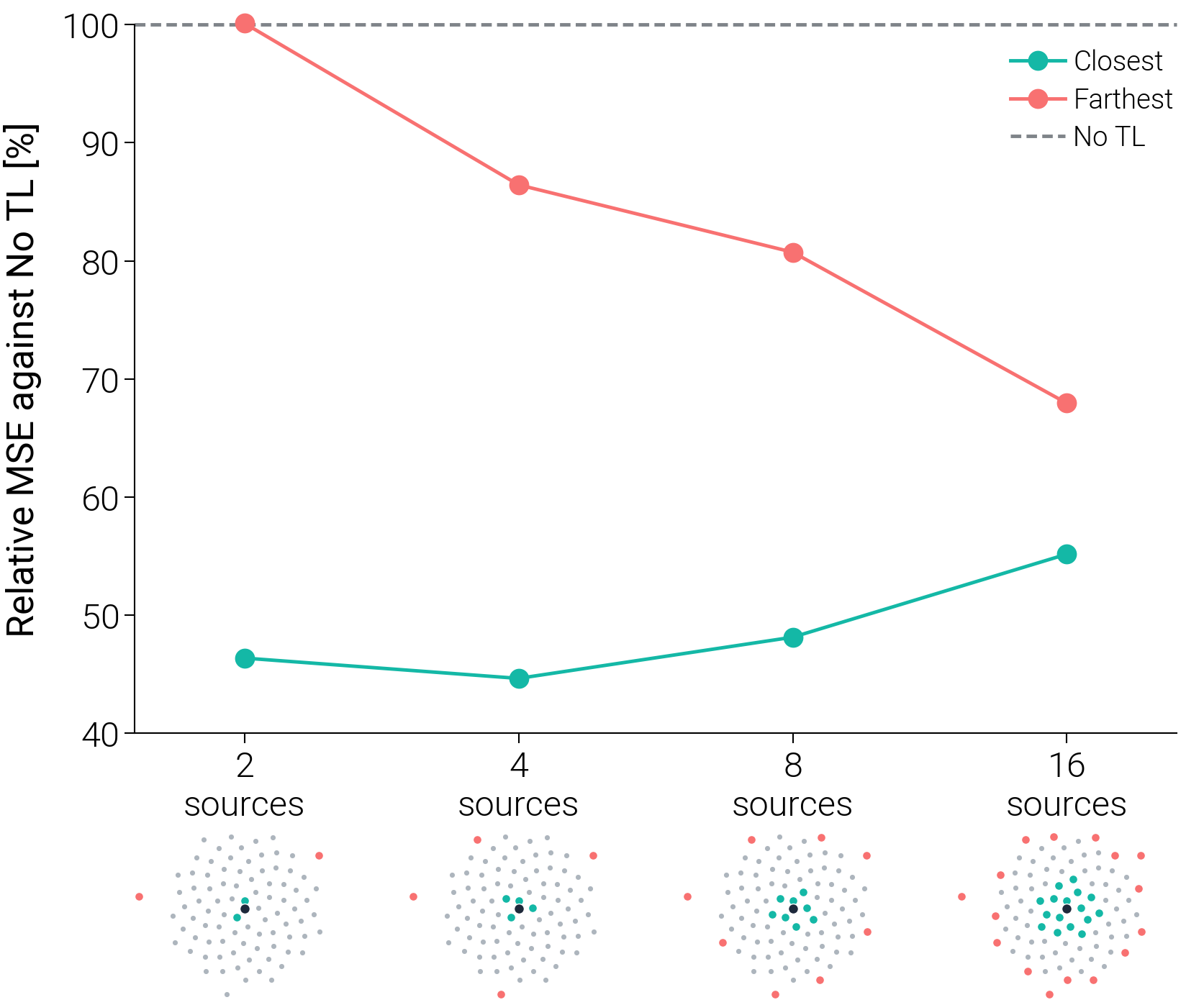
Three hypotheses are validated across all 89 buildings:
- H1: The Closest strategy consistently outperforms the Farthest strategy
- H2: A performance sweet spot exists under the Closest strategy
- H3: Farthest strategy shows monotonic improvement with more sources
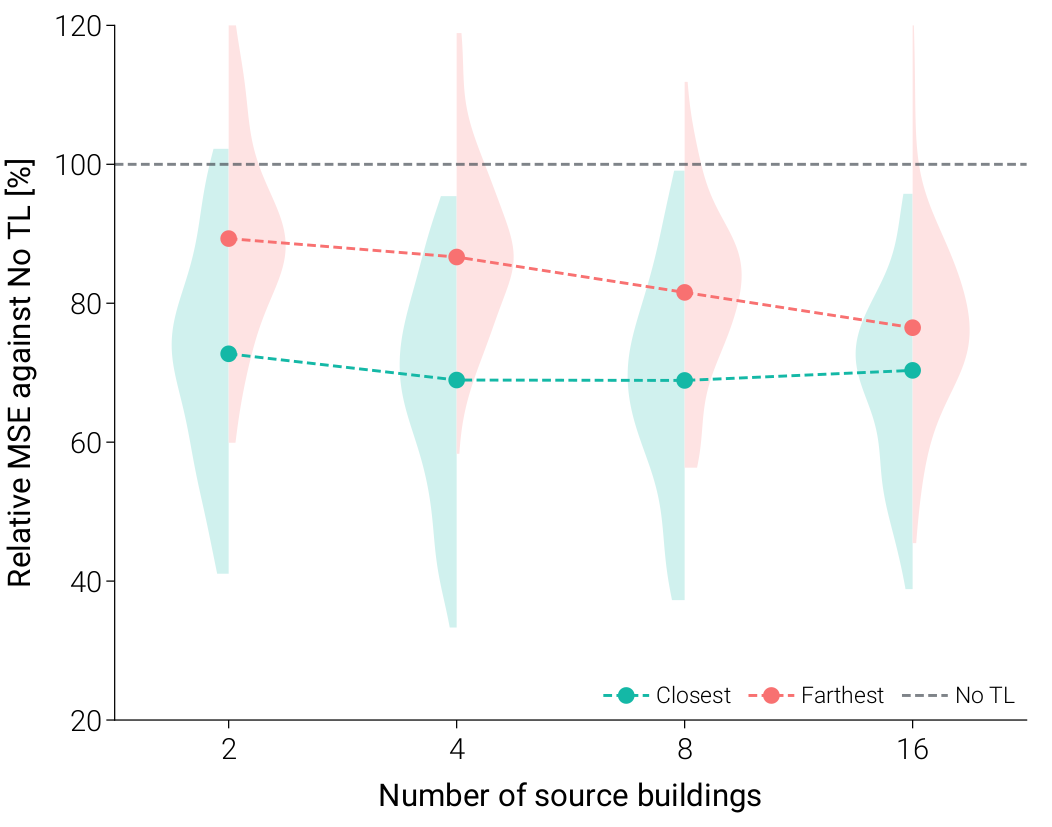
Framework Robustness
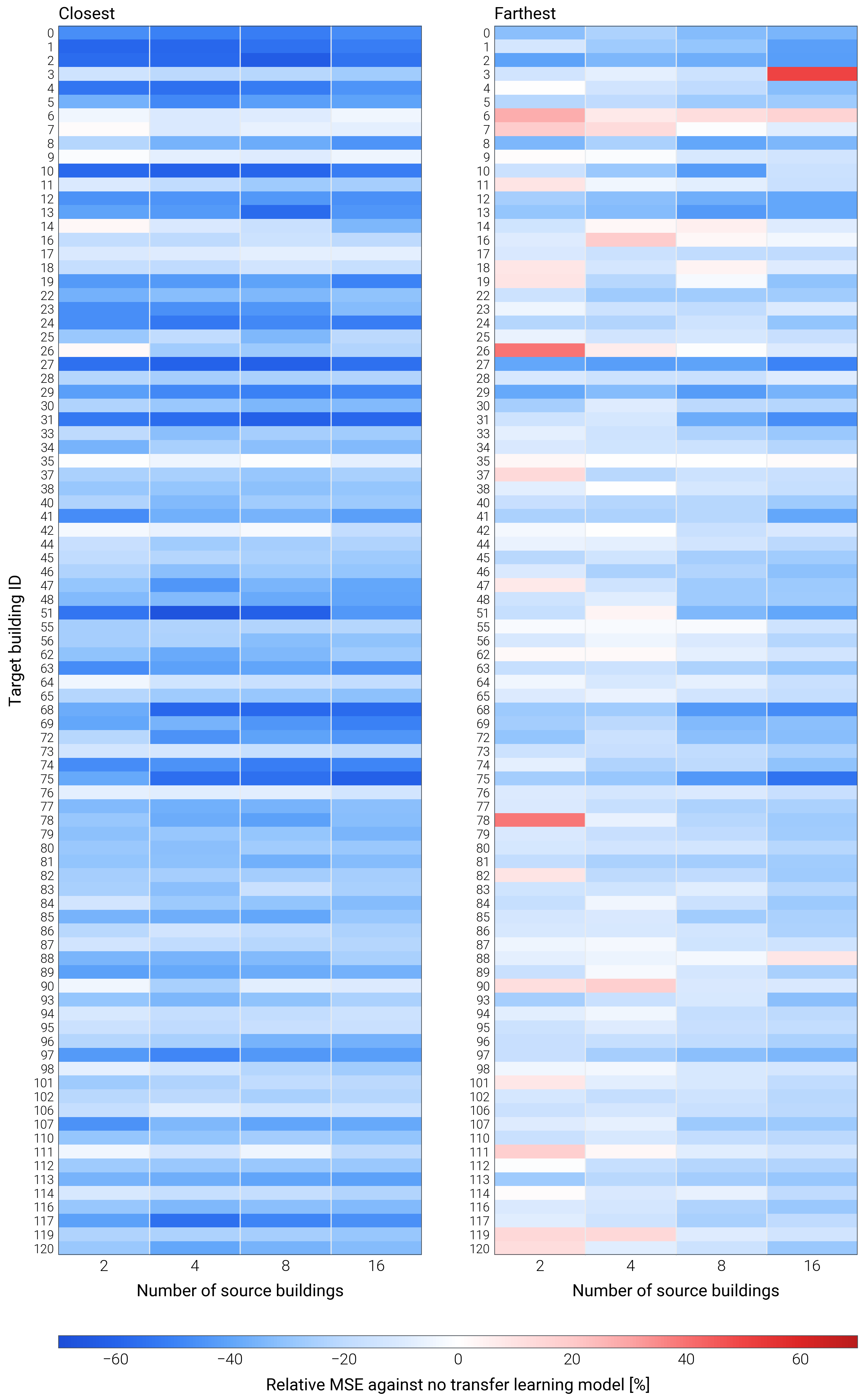
The Closest strategy achieves improvements in nearly all cases, with only 3 instances of marginal degradation (max 2.2%). This demonstrates remarkable stability across diverse building types.
Forecasting Performance
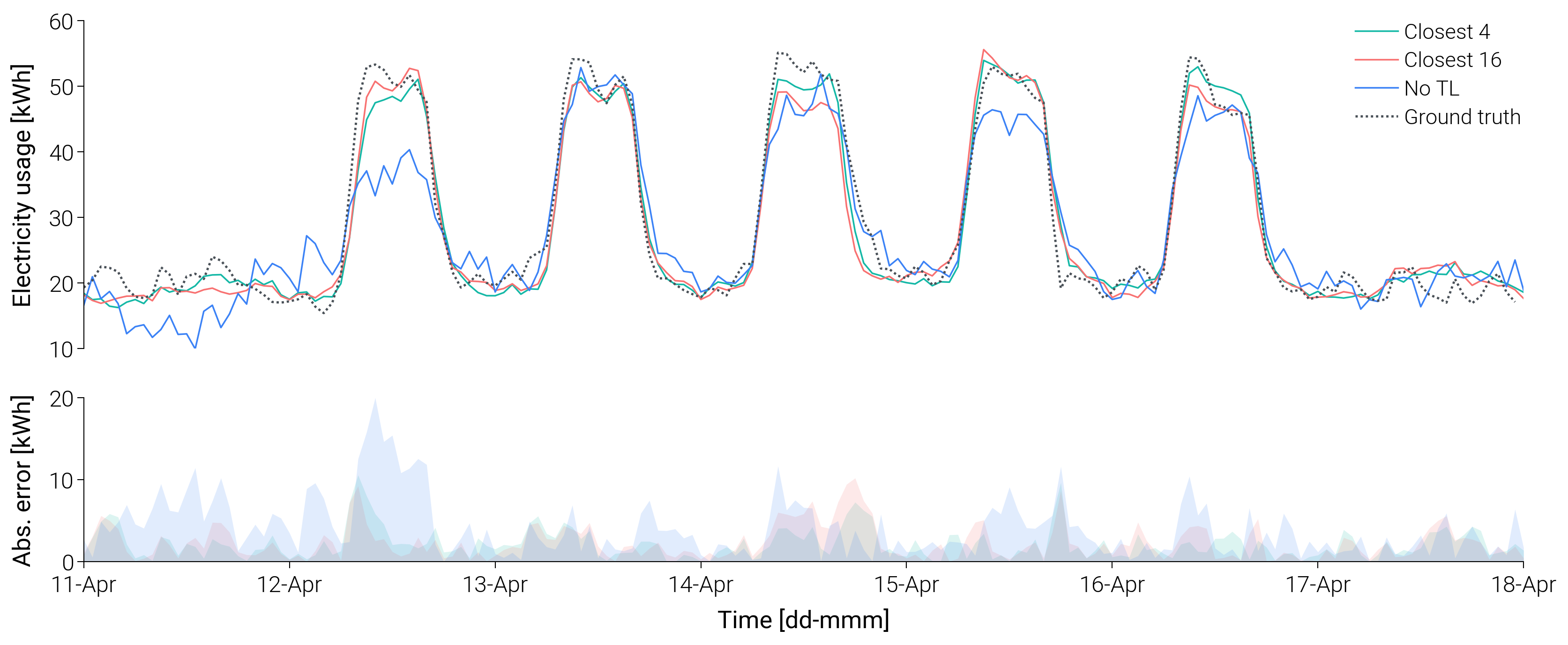
Transfer learning models demonstrate superior stability and generalization. The optimally configured model (Closest 4) achieves better peak forecasting accuracy, while the No-TL baseline exhibits erratic fluctuations and systematically underestimates peak demand.
Comparison with Federated Learning
| Metric | Federated Learning | PPTL Framework |
|---|---|---|
| Privacy approach | Structural locality (trustless) | Regulatory compliance (trusted) |
| Communication | ~608 MB over 100 rounds | ~3.1 MB (0.51% of FL) |
| Client computation | GPU-class hardware required | No local training needed |
| Non-IID robustness | Vulnerable | Robust by design |
| Personalization | Generic global model | Target-specific models |
Contributions
- Metadata-free transfer learning framework — Enables effective TL using exclusively anonymized time-series data.
- Representation distance as transferability proxy — Cosine distance reliably predicts transfer success (99.2% improvement rate).
- Negative transfer as manageable engineering risk — Characterizes the quantity–quality trade-off for systematic decision-making.
- Scalable deployment complementing FL — Only 0.51% communication bandwidth with server-side computation.
Authors
- Wonjun Choi (School of Architecture, Chonnam National University) — Co-first, Corresponding
- Sangwon Lee (Dartwork) — Co-first
- Max Langtry (University of Cambridge)
- Ruchi Choudhary (University of Cambridge)
Acknowledgements
This work was supported by the National Research Foundation of Korea (NRF) grant (No. RS-2023-00277318 and RS-2025-00512551) funded by the Korean government (Ministry of Science and ICT).